摘要
本文主要记录自己动手做人脸识别数据集的整个过程,识别的过程主要分别使用了3中方法实现。
- 通过摄像头采集现实中的人脸
- 从某些明星写真网站,通过爬虫手机明星写真的照片,然后进行人脸定位裁剪和保存
- 通过爬虫手段从互联网上搜索引擎中获取名人的照片,然后对名人照片进行人脸定位裁剪保存到本地
[x] Edit By Porter, 积水成渊,蛟龙生焉。
方法一、通过摄像头实时采集
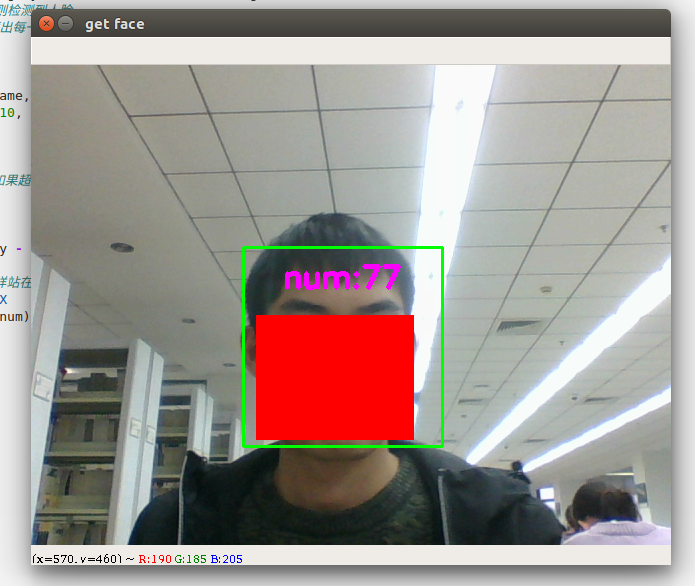
1.1 通过摄像头获取自己的头像
流程如下:
- 加载HAAR检测其中的人脸检测训练好的模型
- 开启摄像头
- detectMultiScale函数检测人脸
- 获取人脸部分的像素
- 保存人脸像素的照片
1 | #-*- coding: utf-8 -*- |
方法二、爬虫专业写真网站
2.1 优美图官网高清图片爬虫
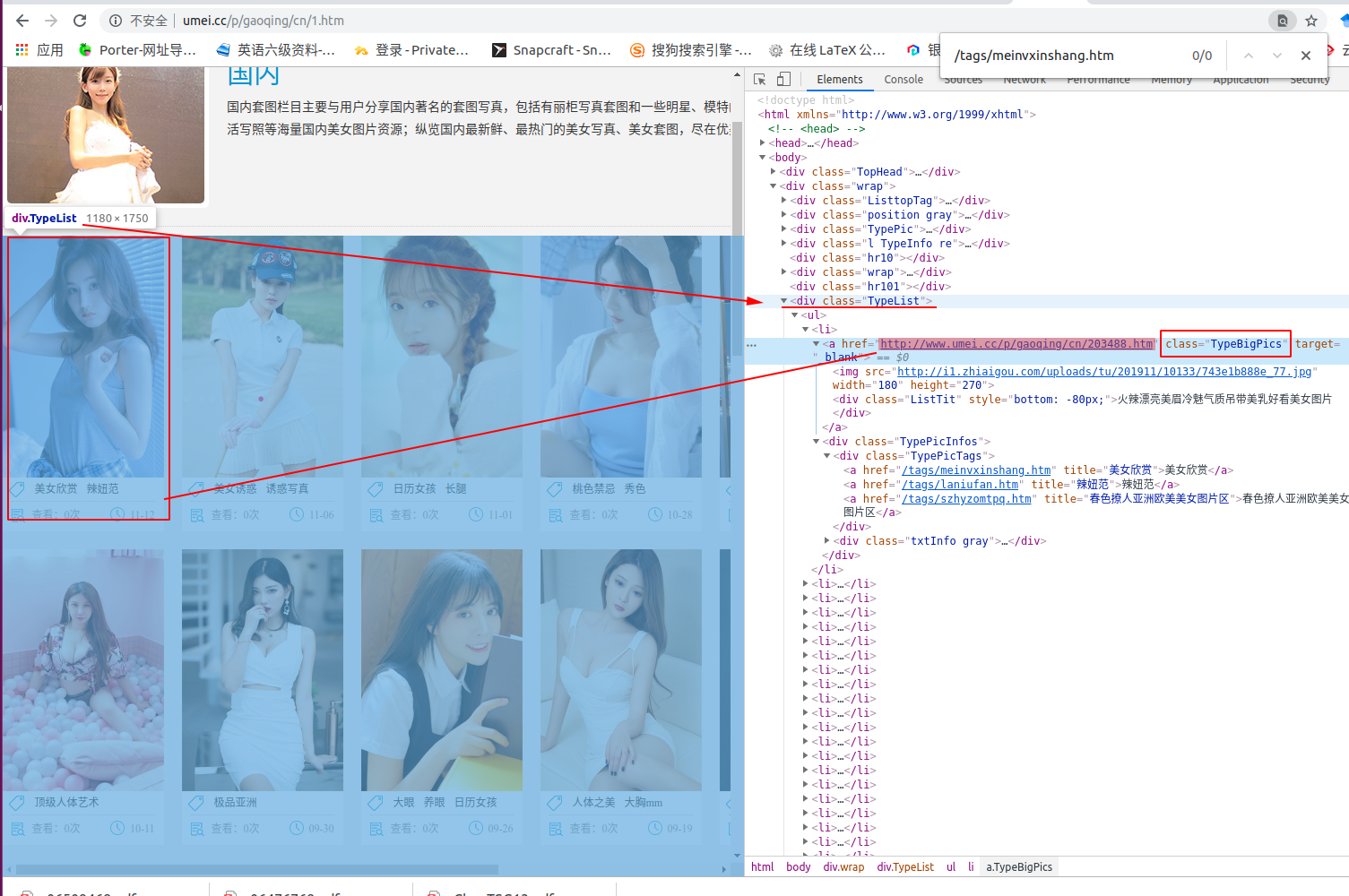
如上图,TypeList类代表整个页面的元素。
而颜色加深的这个 href=“http://www.umei.cc/p/gaoqing/cn/203488.htm” 表示红框中的第一张图片对应的高清照片的地址。而下面的那个链接只是当前显示的非高清的图片缩略图,我们这里只爬取高清的图片,并保存到我们本地文件夹中。
接下来我们转到高清的原图页面,也就是代开这个网址 http://www.umei.cc/p/gaoqing/cn/203488.htm
我们得到如下图的源码对照的界面,途中我加深颜色的链接才是真正的高清原图,我们需要的正是这个高清原图,接着我们就就行request请求,然后下载图片保存下来,就好了。
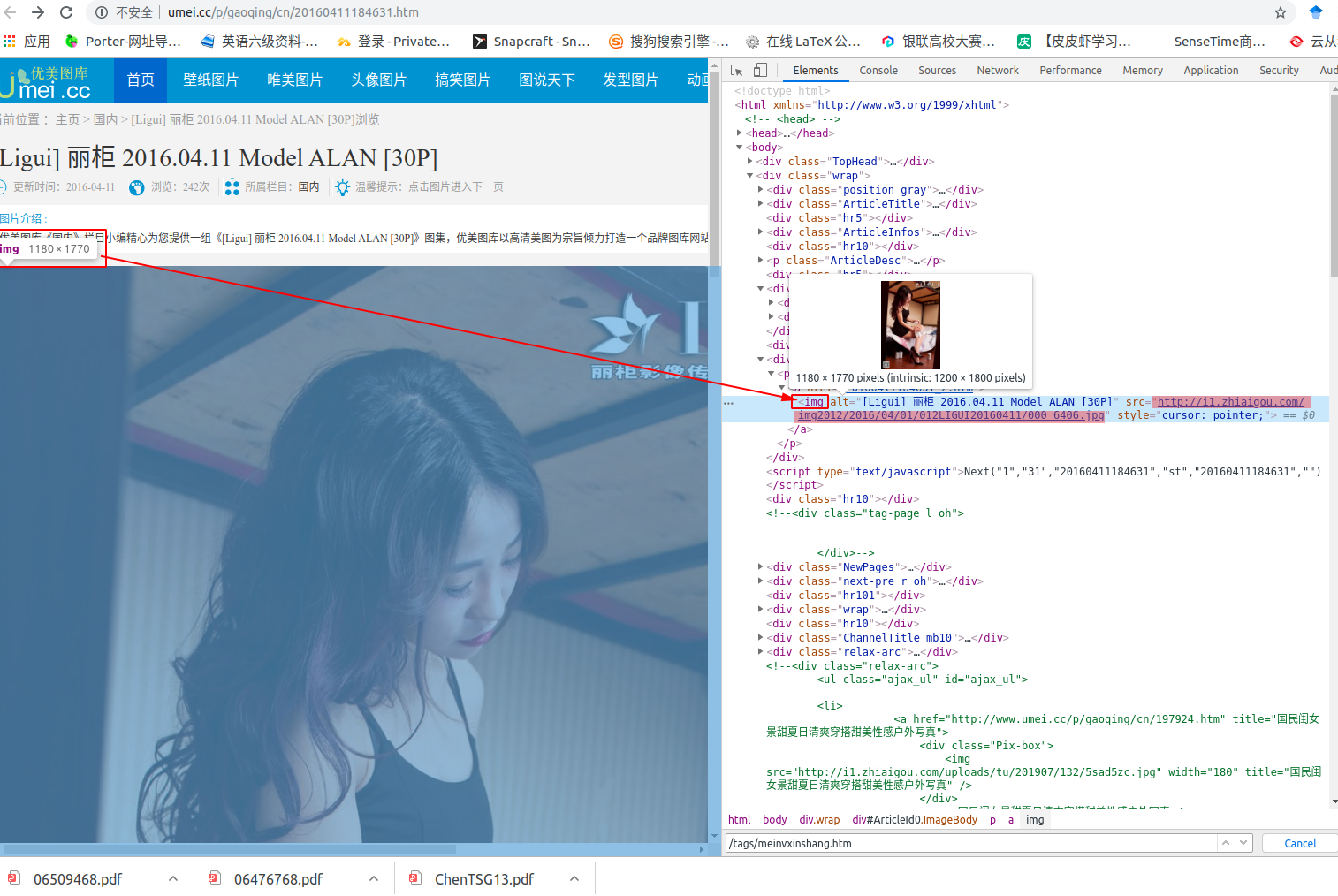
2.2 爬虫技巧
爬虫的工具如下:
- requests
- pyquery
测试一:爬取优美图库网站的美女图片
步骤如下:
- requests.get 请求获取网页信息
- pq(html) 解析网页文本内容
解析网页内容示例代码:
1 | from pyquery import PyQuery as pq |
运行结果:
1 | <link href="http://asda.com">asdadasdad12312</link> |
2.3 爬取他人的写真照片代码
1 | # -*- coding: utf-8 -*- |
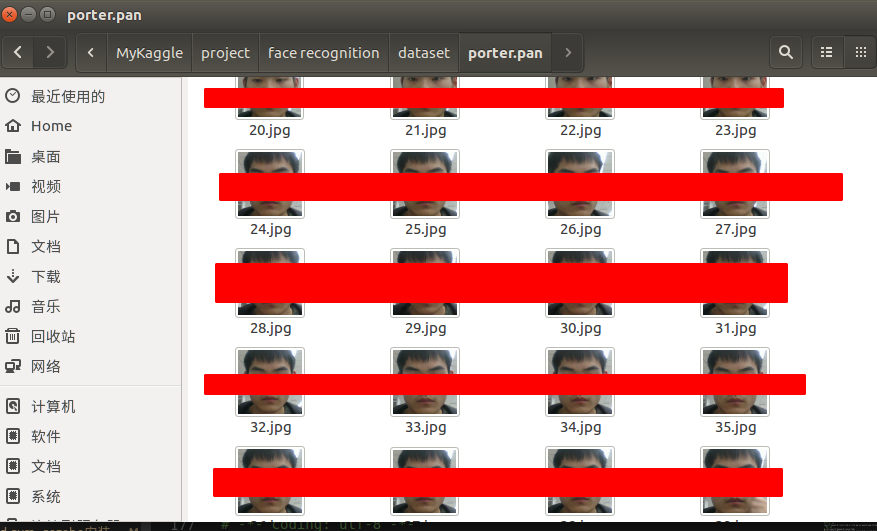
运行代码后就可以看到我们待保存的文件路径中存在了很多张高清美女照片。
(待见高清宅男福利)
下图是我自己爬虫的文件夹中的部分高清照片,仅仅供参考。
方法三、利用专业的搜索引擎
3.1 爬虫爬取必应图片搜索的关键词
urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)
- url:外部或者本地url
- filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据)
- reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
- data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
3.2 爬虫过程介绍
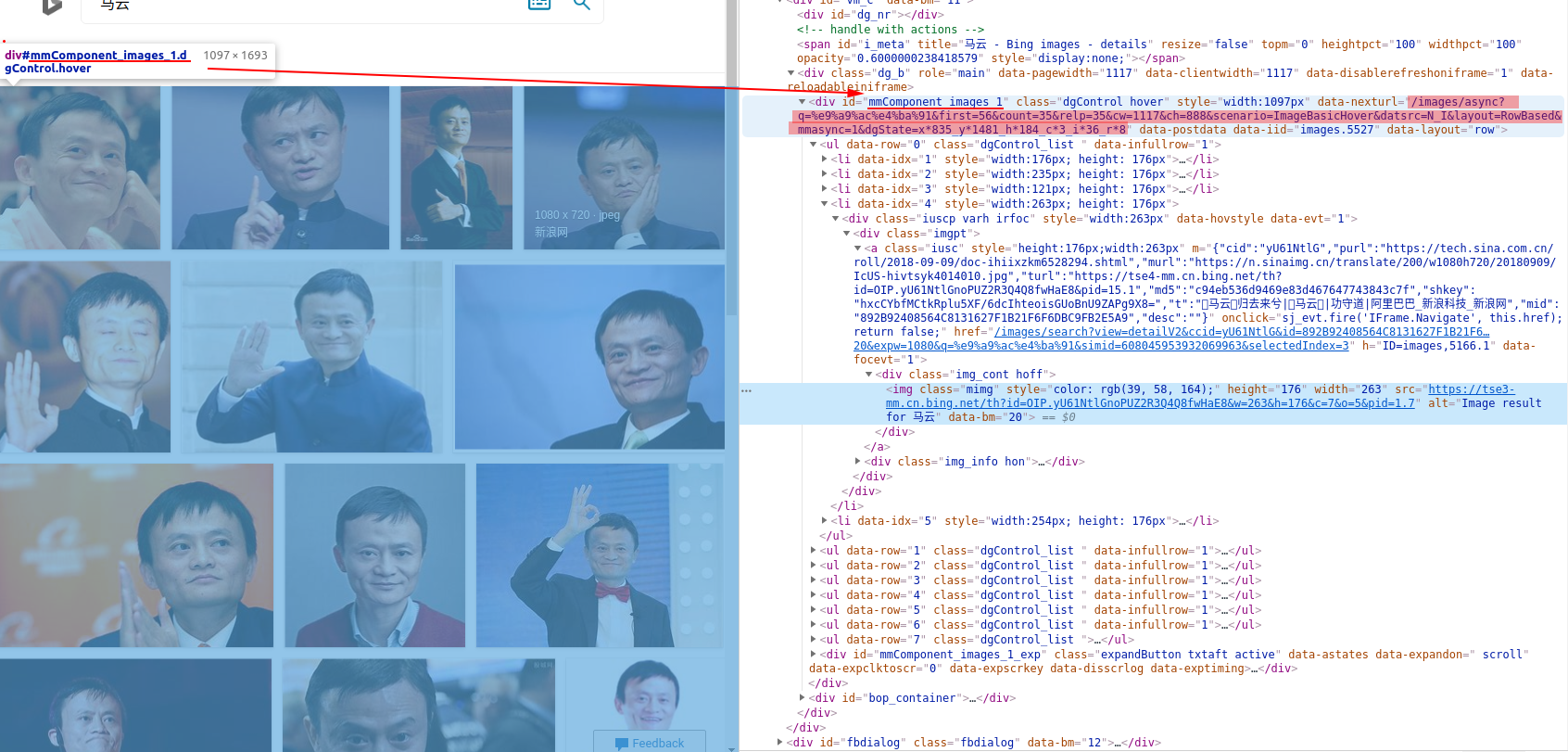
如下图所示,我们进入必应搜索官网,输入关键词,查看网站源码,可以看到下图的内容。
用浅色笔记涂深的链接就是我们需要拿到的链接地址。
1 | url = 'http://cn.bing.com/images/async?q={0}&first={1}&count=35&relp=35&scenario=ImageBasicHover&datsrc=N_I&layout=RowBased_Landscape&mmasync=1&dgState=x*188_y*1308_h*176_c*1_i*106_r*24' |
其中{0} 和 {1}关键字是我们后面方便调节参数的占位符,我们在浏览器中打开,比如搜索关键词为steve jobs.则需要打开下面的链接
1 | https://cn.bing.com/images/async?q=steve+jobs&first=195&count=35&relp=35&scenario=ImageBasicHover&datsrc=N_I&layout=RowBased_Landscape&mmasync=1&dgState=x*188_y*1308_h*176_c*1_i*106_r*24 |
接下来我们在打开的页面中再次查看源代码,如下图所示:
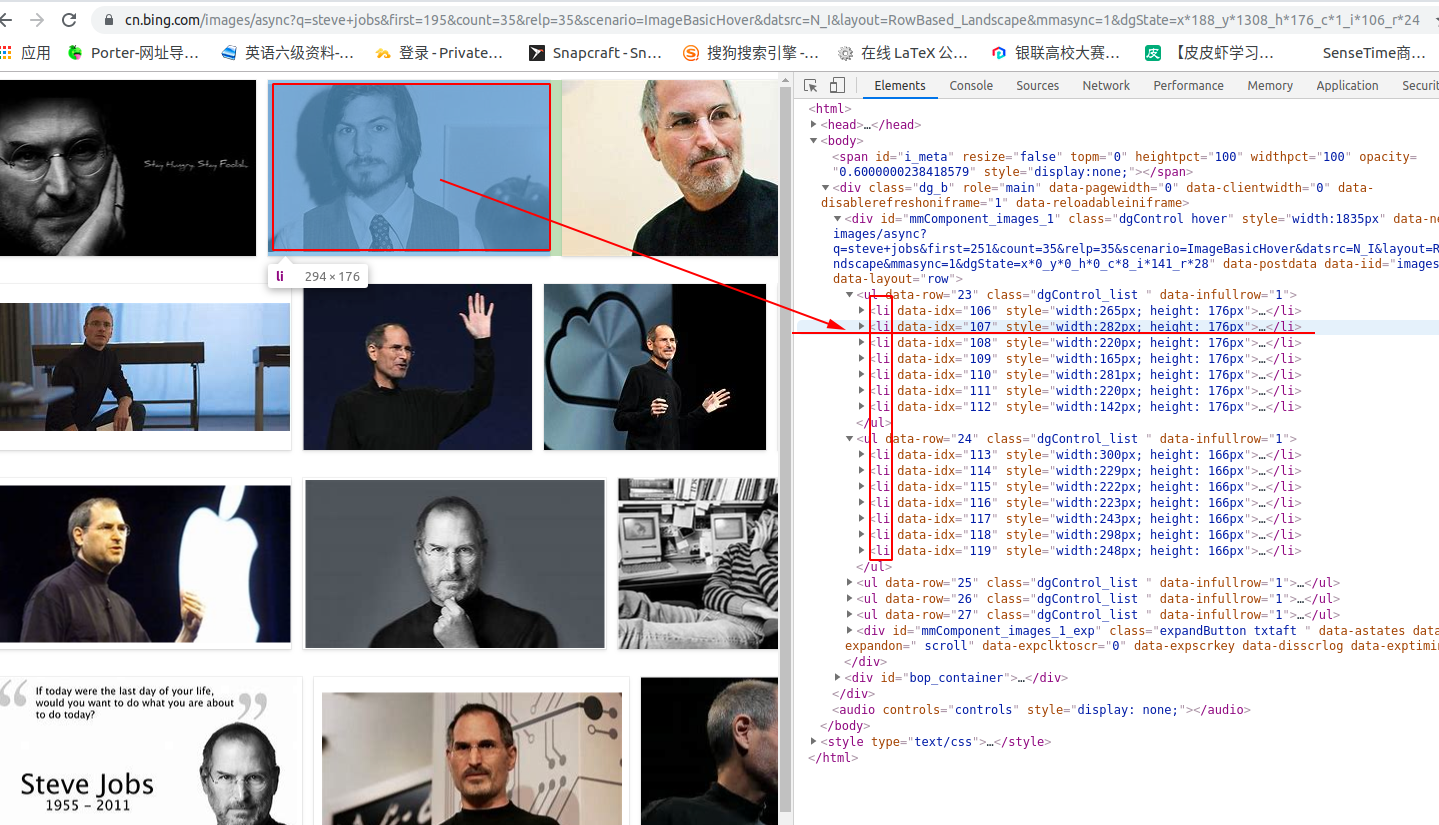
这个源码页面比之前的页面要精简的多了,如图,每个li都代表一张图片,每个图片的真实链接地址,如下图:
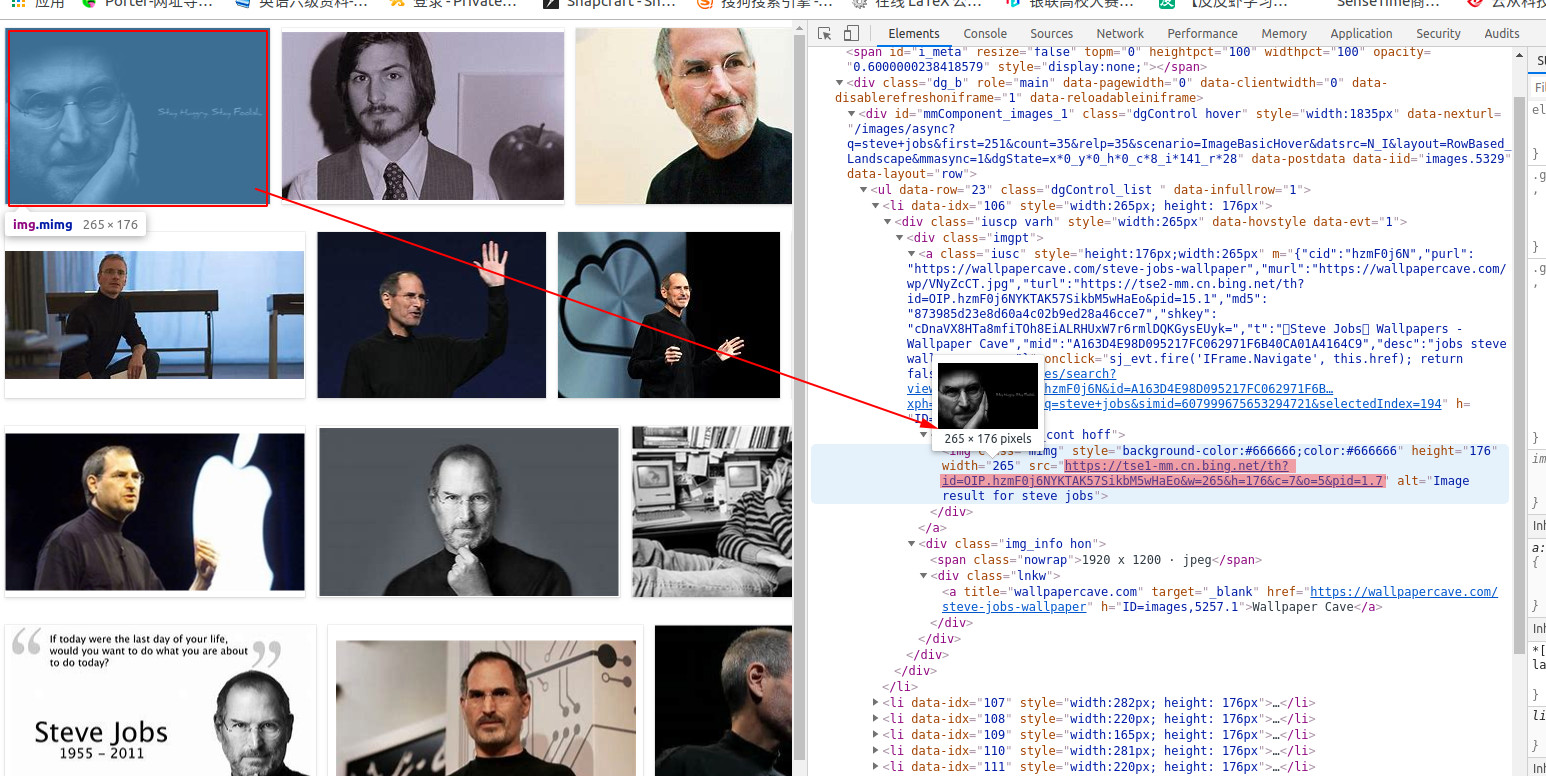
途中浅颜色描出的就是这个图片的真实地址。
我们就需要这个图片,分析到这就差不多了,所以如下代码直接进行爬虫。
3.2 实现的代码如下
1 | import urllib |
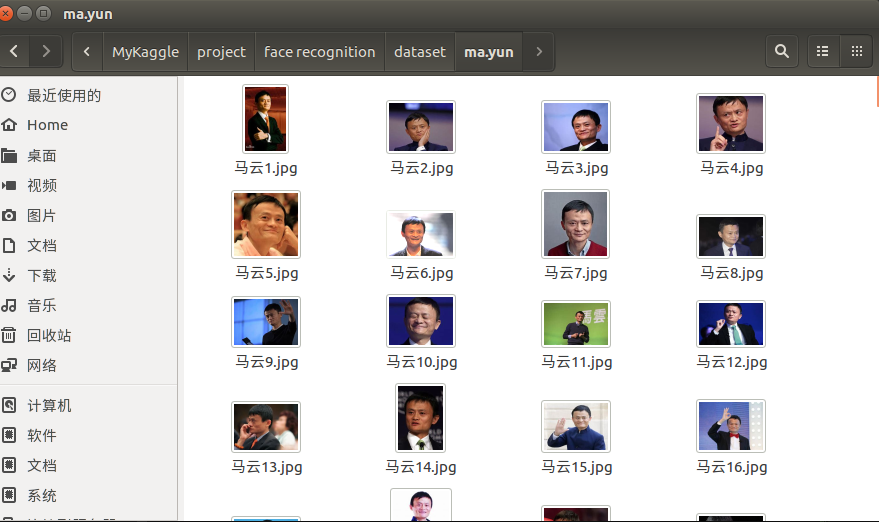
下面是我爬虫到马云的照片